
tldr: Yes.
A recent paper, GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, makes the claim that their new benchmark demonstrates that state of the art reasoning models have critical limitations when it comes to reasoning. Putting aside the fact that they grouped together tiny 2.7 B parameter models (that could fit on your phone) alongside more capable models like o1-preview to arrive at their “up to 65%” performance drop (the number widely repeated by the press), the researchers claim their new benchmark proves that and that the problem “cannot be resolved with few-shot prompting or fine-tuning”.
Putting aside defining what “reasoning” is and how you objectively measure it, I think the problem revealed in their paper is that models are largely trained on tasks that don’t have a lot of trick questions and try to earnestly answer a problem by assuming that the distracting clause is actually important and has to be figured into the solution.
A simple test for this is to tell the model that a question may contain distracting information – but nothing else about the question. If it can both solve trick problems and ones with distractors reliably, then there’s probably more going on.
In this image from the paper you can see that o1-preview overcomplicates what should be a simple problem from their GSM-NoOp benchmark. But is this a failure of its reasoning ability or a training data problem – like a homeschooled kid raised in a home where nobody ever lied to him?

So let’s try an experiment… In the first run we give o1-preview the GSM-NoOp problem the researchers showed it failing on (one of the few examples in the paper I could find it repeatedly failed most of the time.) It scores 0 out of 10. The distracting clause about donating baked good certainly trips the model up…
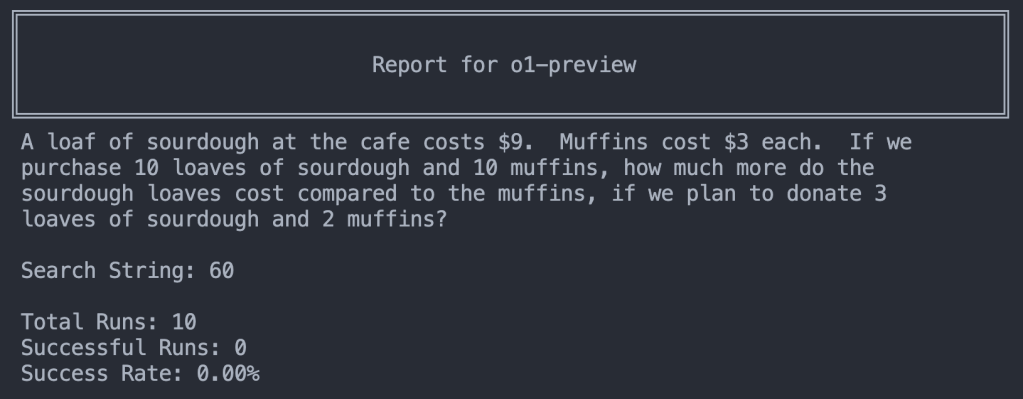
Okay, but what if we merely tell the model this could be a trick question with a prompt like this? All we’re basically saying is “This could be a trick”. There are no multi-shot examples of how to solve the problem, just a clue that a model that would only be able to use if it could…um, reason(?):
This might be a trick question designed to confuse LLMs with additional information. Look for irrelevant information or distractors in the question:
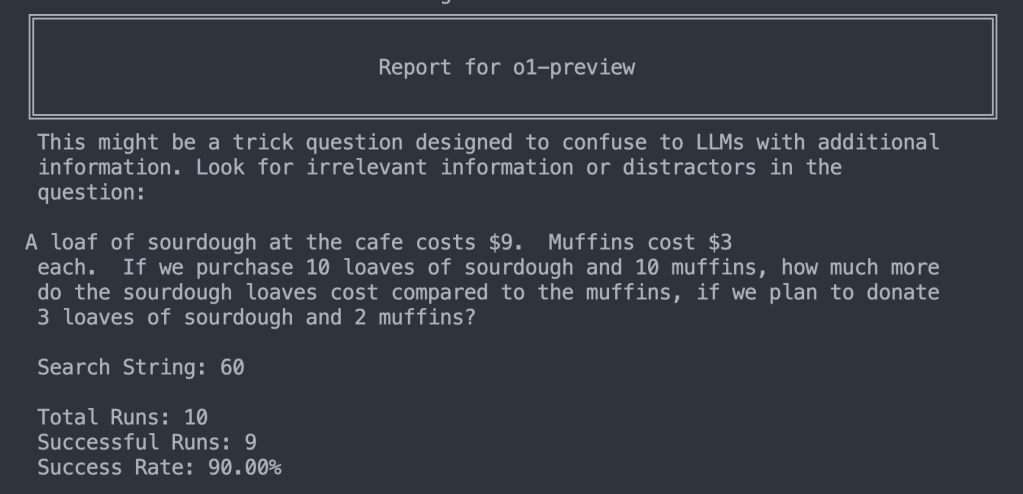
90% success! With one prompt addition that has no additional information about the specific problem the model goes from 0% to 90%. (This is despite my superfluous “to” in the added prompt.)
I’d say this is evidence this problem can be solved with prompting and/or fine-tuning. Also, this suggest the GSM-NoOp dataset might not be as formidable as presented if you can just paste this prompt in front of every problem. But to be sure, let’s give it a version of the problem with the pre-prompt but no distractor. Will this make the model assume it’s a trick and get the problem wrong…ironically making the distraction warning a distraction?
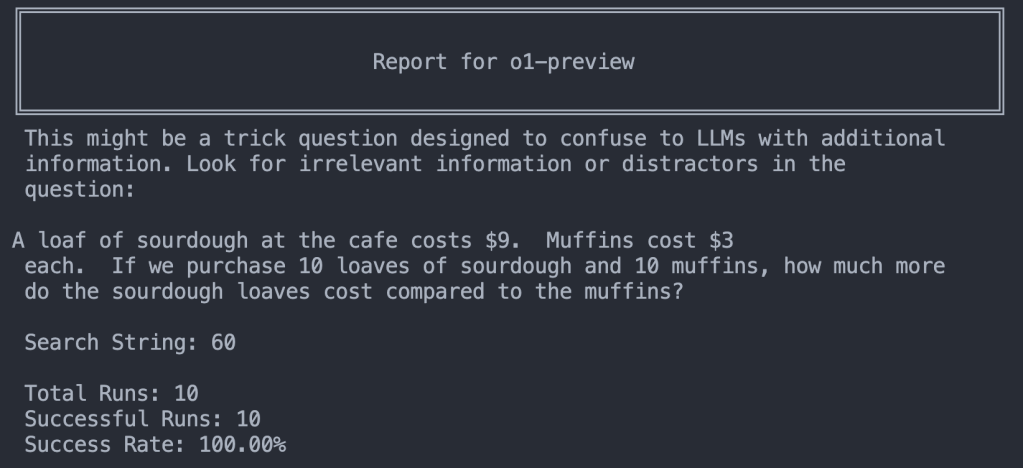
Nope! The hint didn’t throw it off from a normal problem. o1-preview scores 10/10 correct!
While one problem tried several different ways isn’t exactly a rigorous evaluation it’s pretty interesting signal. What if we drop down a class and use OpenAI’s smallest GPT-4-class model, GPT-4o-mini? This isn’t even a fancy “reasoning” model.
First just the problem with no added prompt:
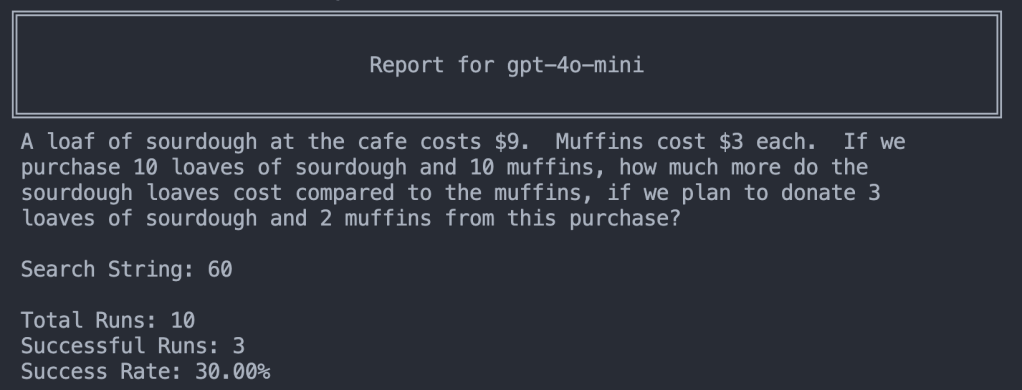
GPT-4o-mini gets 3/10 without the prompt – which is 30% better than o1-preview and adds support to the idea that this is a training data issue and not a reasoning issue.
But will our little prompt work with little GPT-4o-mini?
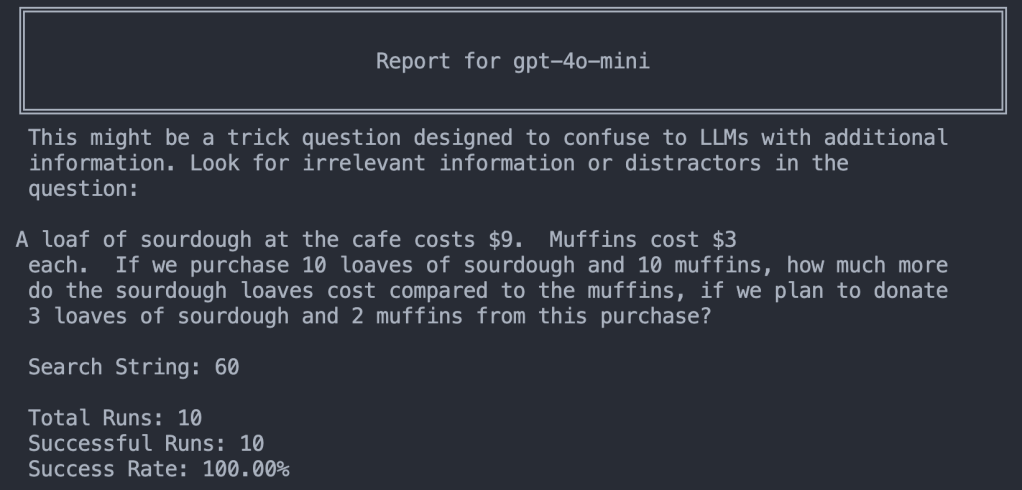
Boom. Mighty little GPT-4o-mini scores 10/10 with the prompt!
Lastly, just to check if the prompt might have a detrimental effect on a normal problem, let’s check with no distractor:
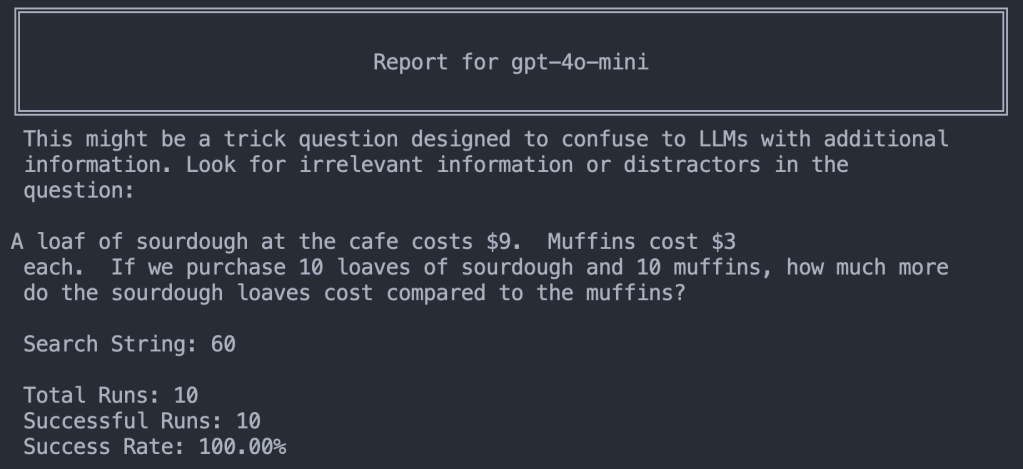
10/10! It scored 100% when you give it the prompt and a question with no distractor.
If this simple prompt works I’m willing to bet fine-tuning a model on problems generated by the GSM-Symbolic and the GSM-NoOp templates with instructions about looking out for trick questions will make the these benchmarks not as useful as intended.
Does this mean that models like o1-preview and GPT-4o-mini can actually reason? I’ll let you know after we have a solid test for human reasoning and can compare them to the average human. Meanwhile, I think the boundaries of what we consider “reasoning” will continue to expand towards the horizon…as will the goalposts.
Additional thoughts:
- The researchers didn’t try to do any creative prompting around the problem. That’s fine…but odd to me. I didn’t have to think too hard to find a way to prompt around the GSM-NoOp problems. Neither Riley Goodside or me are that hard to find…
- There were no comparisons to human scores in the paper. I think it would have been interesting to see how well the average college student would perform on a similar test – especially with and without warnings about trick questions.
- I think if anything reasoning is a spectrum. Either a score means something or not. The fact that GPT-4o-mini and a simple prompt enhancement could get 100% on the toughest example in the paper should indicate by their own definition that something is going on.
- Using very small models like a 2.7 billion parameter Phi-2 model felt a bit like putting a thumb on the scale to bring down the class curve
- I couldn’t get o1 or GPT-4o to reliably fail on some of the other examples they showed.
- I have come to the realization that people will spend more time re-posting papers like this than actually trying the problems posed in them or looking closer at the results.
