
TLDR: How to boost GPT-4 with Vision’s capabilities with a simple prompt addition.
A recent paper How Far Are We from Intelligent Visual Deductive Reasoning? points out the limitations in visual reasoning in image models like GPT-4V. Like other related papers, I think the investigators are directionally correct (these models don’t have human-level reasoning and there’s plenty of room for improvement) but I think their findings were at least partially negatively impacted by their prompt design.
In their study they present GPT-4V and other models with prompts and images in various combinations including segmenting the image into different sections. For the zero-shot method they used this prompt and this puzzle images – which we’ll focus on here.
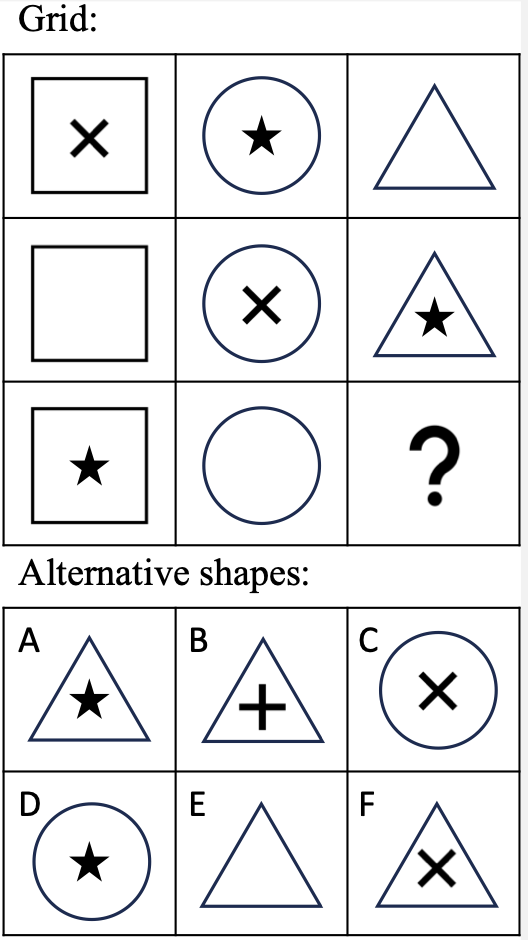

In my test using their simple zero-shot prompt, GPT-4 Vision gets the answer to the example puzzle correct 29% of the time. Above what chance would expect (there were 6 possible choices), but nothing exceptional and making it evident that with that prompt the model has difficulty with even the most simple of visual reasoning tasks.
Note: In some runs the model made comments about some shapes having blue borders. In the world of prompt engineering, once may be random, twice, and there’s probably something there. Sure enough, when I put their image into Photoshop and bumped up the saturation it was clear that some of the borders were dark blue. The coloring was consistent and wouldn’t lead to a different conclusion for that specific puzzle – but it’s a good reminder that these systems often see details we may not.
In my experience with GPT-4 with Vision at OpenAI helping find interesting capabilities it became apparent that just like text prompting, you need to get the model to pay attention to details that matter. Simply saying “think step by step” often isn’t enough. You have to tell the model to pay attention to specific details.
For example, when giving GPT-4V a theory of mind test to see if it understood what different people in an image would be capable of seeing, it was helpful to first ask the model to look at the scene and understand the placement of everything in it before answering the question. Although this instruction was given in one prompt with the query, the effect was that GPT-4V was much better at answering the question. I found the same for complex (Rube Goldberg-style) machines.
Without asking the model to understand the scene it’s able to understand that it’s being given a theory of mind test but then goes on to completely fail it:
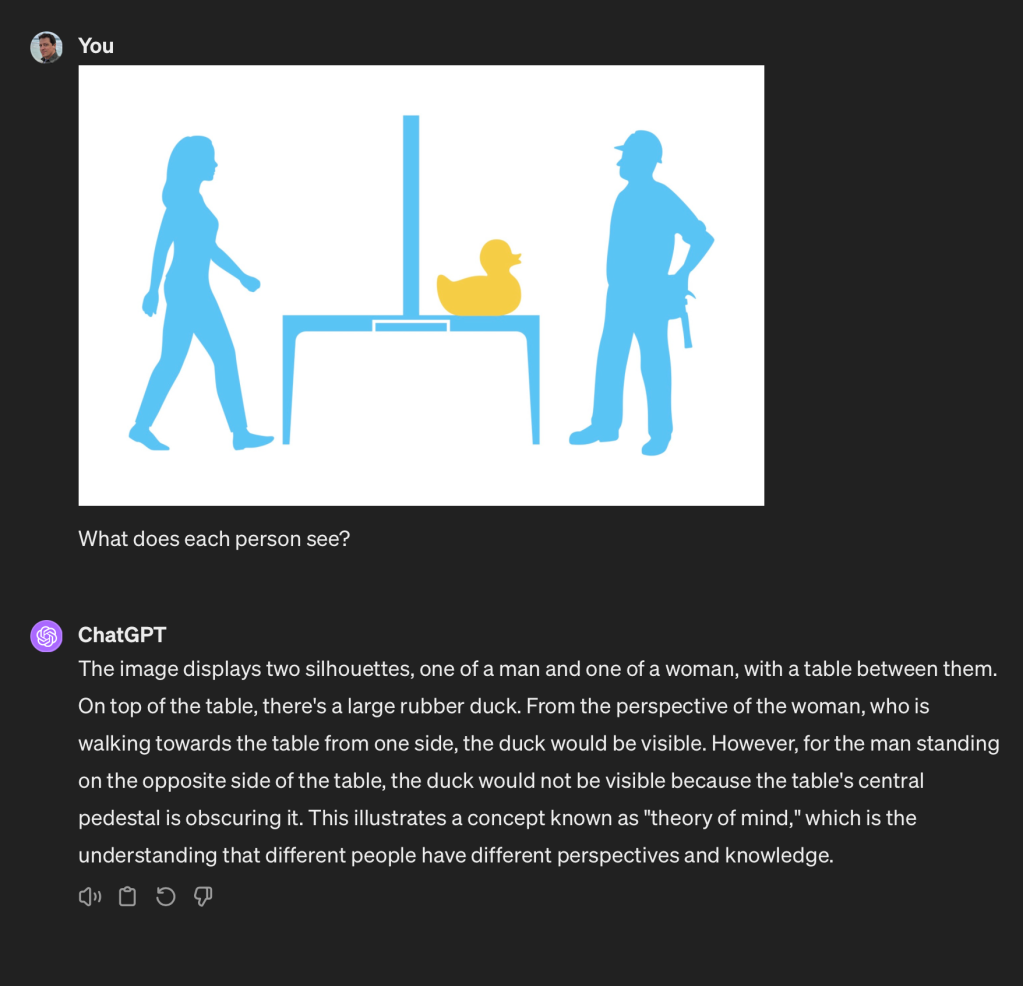
The model knew what it was being tested for but still failed. My naive theory is that when it gets image data it’s making a rough sketch based on a generalized pattern. Similar to how our hippocampus fires when we enter a room, we’re really just trying to understand where we are in 3D space and if there are any predators about to eat us. We’re not as concerned with our couch pillows or the title of a magazine.
Adding one simple instruction to the prompt increases the chance of success:
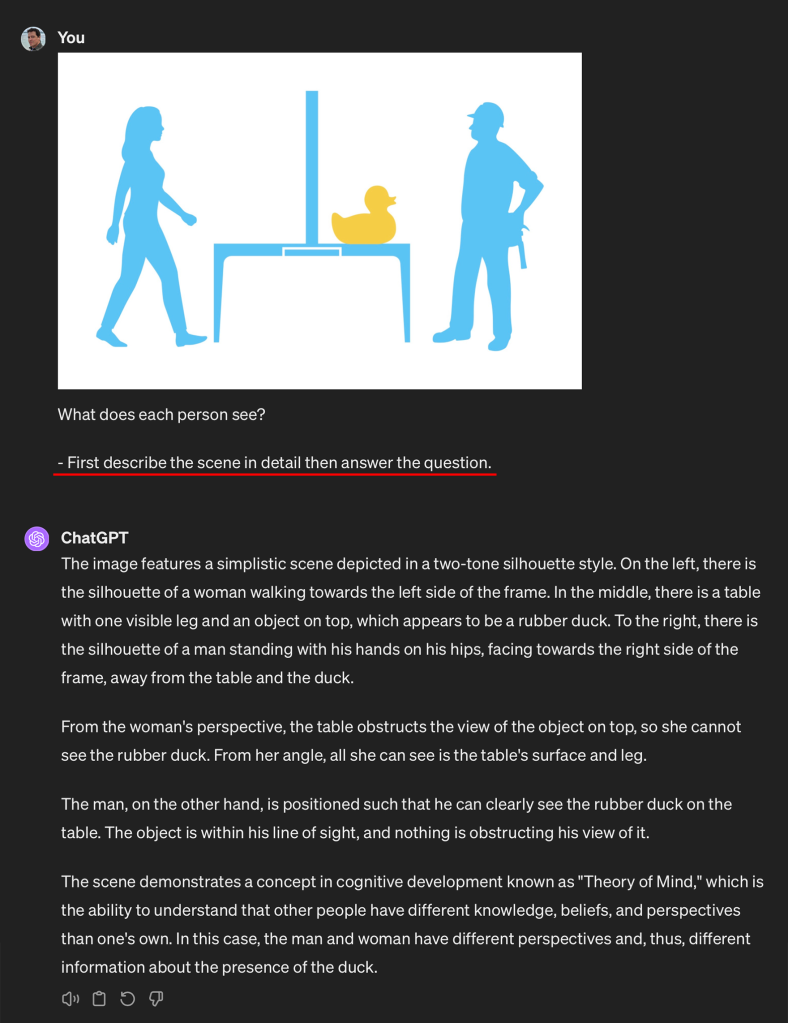
With one sentence added to the prompt the model understands the test and is able to correctly identify what each person sees.
Based on this, my first reaction to the prompt in the paper was that it was probably too simple and didn’t ask the model to really engage and pay enough attention to be able to solve the puzzle. Like my previous example, if it didn’t notice a detail it will hallucinate about it later.
Models like GPT-4V don’t have perfect information about every pixel and its relationship to every other one – that would be mathematically impossible – they make assumptions about what’s important. Without knowing what to look for, it might assume crosses and plusses are the same thing because they’re both crossed lines (something GPT-4 with Vision would do with the puzzle.) The same for understanding the relationship of objects in 2D space. A spoon is remembered as being “next to” but not to the right or left of a coffee cup. If asked afterwards it will make an educated guess (what we call a “hallucination.”)
I think that failure point about relative positioning is interesting because it shows that the models pay attention to things differently than we do. These differences in how we prioritize visual input can be fascinating. I did a firsthand experiment on this with animal perception where I tested an underwater stealth suit designed to fool great white sharks (You can find out if I got eaten or not in Andrew Mayne: Ghost Diver now available on HBO Max.) My hypothesis was based on the idea that because of hundreds of millions of years of evolution, sharks have very efficient image recognition algorithms and their daytime visual perception might rely on spotting silhouettes (and not be too dissimilar from simple shape recognition algorithms we find in vision machine learning.) Systems like GPT-4 with Vision use their own efficient algorithms and will make ad hoc guesses about what’s important and then try to rationalize about them later on. Because of this, I think it’s important when prompting to be specific about how to pay attention.
We can test this by adding instructions that don’t explicitly give away the answer, but tell the model how to reason through it visually. The first part of the researcher’s instructions are the same. The added part is a general purpose “Pay attention!” vision prompt:
There is a grid of 9 boxes, one of which is empty (marked as ?). You have to choose which of the 6 alternative shapes (A-F) should be placed in the empty box in order to complete the pattern that connects the shapes. Finally, provide your prediction as Answer: “X”.
- Describe the items in detail with specific attention on position.
- Pay attention to simple details that might be different.
- Use a notation to hold your descriptions.
- Revisit your descriptions for consistency.
- Come up with a hypothesis.
- Create a test based on your hypothesis – don't simply agree with yourself. Run the test.
Notice that there is nothing specific about the test in my prompt addition. The added section is simply a checklist of things to do that could be applied to virtually any image task.
Let’s break down the steps:
Describe the items in detail with specific attention to position.
The purpose of this is to tell the model that details and position matter. I might get a different result if I told it to focus on colors or emotions if people were present. But for general purpose tasks it’s a good callout.
Pay attention to simple details that might be different.
This is another encouragement to the model that detail matters. I don’t want the “gestalt” of the image but the relationship of everything in it.
Use a notation to hold your descriptions.
This instruction tells the model to track what it’s noticing. This keeps it consistent and in theory helps prevent it from “forgetting” something. I could be more explicit about how to annotate what it has observed, but find it works best to trust it to use its own method. That said, any easy way to improve the model via fine-tuning or prompting would be to reinforce it with notation methods that most often resulted in success.
Revisit your descriptions for consistency.
This is a self-check telling the model to be consistent. I don’t know if by itself it’s useful, but with the other instructions reinforces the idea that it has to revisit its process.
Come up with a hypothesis.
The goal here is to have the model state its theory. We want it to explicitly state its reasoning. This is useful for the following step but also helpful if you want to do some forensics and figure out why the model got something right or wrong.
Create a test based on your hypothesis – don’t simply agree with yourself. Run the test.
Having the mode test its theory can be helpful. I tell it to not just agree with itself so the test is a bit more robust – but there’s an argument to be made that even this test is really just a post hoc hallucination. As long as more neurons are involved in solving the problem, the better. I’ve seen forms of this prompt leading to really long back and forths where the model realizes it made a mistake and keep trying until it succeeds or gives up.
My prompt engineering may sound fine in theory, but what actually happens if we put it to the test and use the same image and the modified prompt?
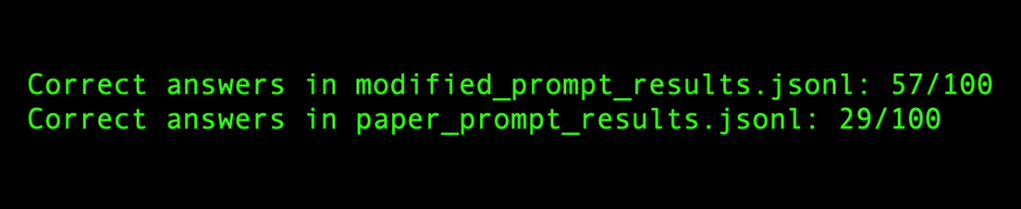
Out of 100 runs with this prompt the model gets the correct answer 57 times (a success rate of 57%). Far from perfect, but a 96.55% improvement over the research study’s 29%. While I don’t know if a perfect score is attainable, I suspect a more nuanced prompt, one selected by the model or an advanced few shot example (showing the model methods for breaking similar problems down) could result in even more improvement.
I also have to point out that I only tested this with one image from their testing examples and I can only speak to the results for that. I’m sure testing on much longer runs and with other puzzles will result in a lot of variations. Everything might fall apart with other images, but my intuition is that you can get better results from GPT-4V for tests like this if you use a more explicit prompt like the one I described.
Conclusion
If you’re working on vision related reasoning tasks with GPT-4V, prompting really matters. Even general purpose vision prompts can improve the chance of success. If you’re looking to do specific tasks in industrial applications or robotics, pay close attention to what you’re telling the model to do and pre-brief it as much as possible about the kind of task you’re asking it to perform. Additionally, fine tuning with instructions that help break different images down into useful details will probably boost performance.
If you’d like to run this test yourself check out my GitHub repo: https://github.com/AndrewMayneProjects/Vision
